A pre-migration analysis is an important step to take before migrating your Oracle database to MongoDB. It involves assessing your existing database and infrastructure to ensure a smooth and successful migration process.
Here are some key areas to consider during your pre-migration analysis:
- Data model : MongoDB is a document-based NoSQL database, whereas Oracle is a relational database. You will need to map your existing Oracle data model to a document-based data model that is compatible with MongoDB. Analyze the relationships between data in Oracle and determine how they should be modeled in MongoDB. Depending on the complexity of the relationships, you may need to use embedded documents or references between documents. More on this topic can be found in my earlier article.
- Query analysis: Analyze the queries that the application will perform on the data in MongoDB. This analysis will help you to determine the structure of the documents, fields to include in indexes, and the type of relationships to model in the schema.
- Indexes: Identify the fields that will be frequently queried and create indexes for them. This analysis will help you to optimize query performance in MongoDB. In addition, Indexes are used to speed up data access and retrieval, and they can have a significant impact on the performance of the migration process
- Assess data consistency: Ensure that data is consistent and free from corruption before migration. Run checks on the database to ensure that data integrity is maintained during migration.
- Evaluate data volume and size: Determine the size of your database and the number of objects it contains. This will help you estimate the time and resources required to complete the migration.
In the following sections of this article, we’ll look at how to get some of these analyses performed on an Oracle database, which can aid in schema design and migration.
Data Dictionary
The Oracle Data Dictionary refers to a set of read-only tables and views that contain metadata about the database objects, such as tables, columns, indexes, constraints, views, users, and privileges.
By querying these tables and views, users can retrieve detailed information about the structure and contents of the database objects. This information can be used to analyze the database schema, optimize queries, and perform other tasks related to database management and maintenance.
Metrics
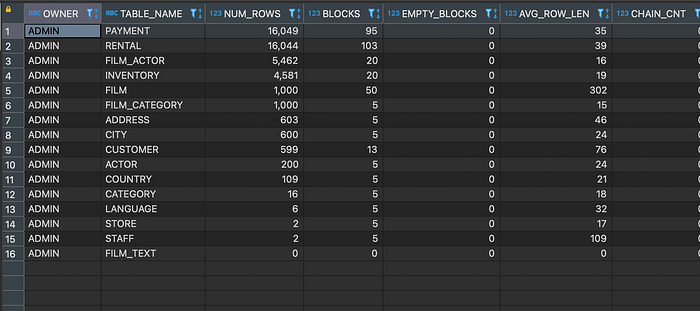
In Oracle, you can get table metrics such as table size, number of rows, number of blocks, and number of empty blocks using the DBA_TABLES view. Below is an example query to get the table metrics for all tables in a schema:
SELECT owner, table_name, num_rows, blocks, empty_blocks, avg_row_len, chain_cnt, avg_space
FROM dba_tables
WHERE owner = 'ADMIN'
ORDER BY NUM_ROWS DESC;
This query retrieves the owner, table name, number of rows, number of blocks, number of empty blocks, average row length, chain count, and average space for each table in the specified schema. You can modify the WHERE clause to retrieve the table metrics for a specific schema, or remove the WHERE clause altogether to retrieve the table metrics for all schemas in the database.
Partitions
To get partitions for all tables in a given schema in Oracle, you can use the DBA_TAB_PARTITIONS view. Here’s an example query
SELECT table_name, partition_name, high_value
FROM dba_tab_partitions
WHERE table_owner = 'ADMIN'
ORDER BY table_name, partition_position;
This query retrieves the table name, partition name, and high value (i.e., the maximum value for the partitioning key in that partition) for each partition of each table in the specified schema.
If you only want to see tables that are partitioned, you can use the DBA_PART_TABLES view instead:
SELECT table_name, partitioning_type
FROM dba_part_tables
WHERE owner = 'ADMIN'
ORDER BY table_name;
This query retrieves the table name and partitioning type for each partitioned table in the specified schema.
For the above schema, we don’t have any partitions. In general this will help in stratergizing the Sharding requirements during schema design.
Indexes
To get all the indexes for a given schema in Oracle, you can use the DBA_INDEXES view. Here’s an example query:
SELECT owner, index_name, table_name, uniqueness, index_type, status
FROM dba_indexes
WHERE owner = 'ADMIN'
ORDER BY table_name, index_name;
This query retrieves the owner, index name, table name, uniqueness (i.e., whether the index allows duplicate values or not), index type, and status (i.e., whether the index is valid or invalid) for each index in the specified schema.
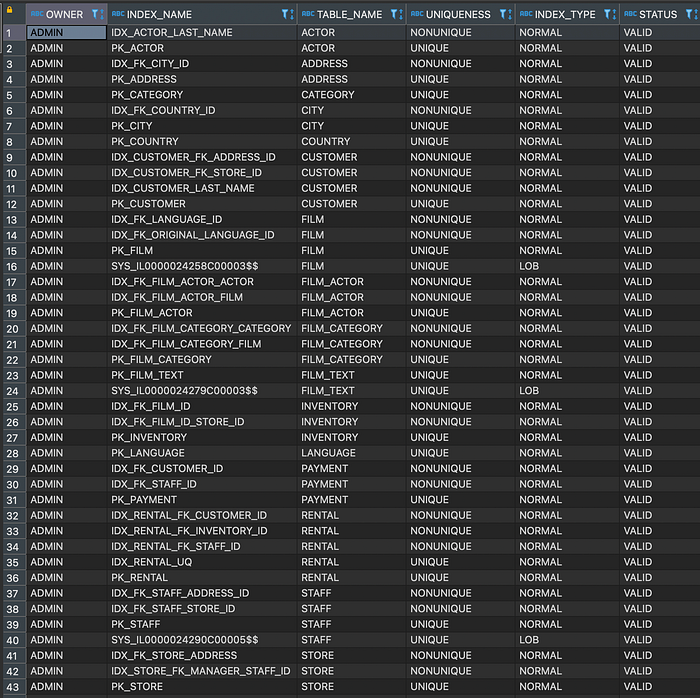
We can further do analysis on which indexes are frequently used to come up with an indexing strategy in MongoDB.
Also use these indexes for efficiently splitting the data during extraction.
Relationships
One to Many
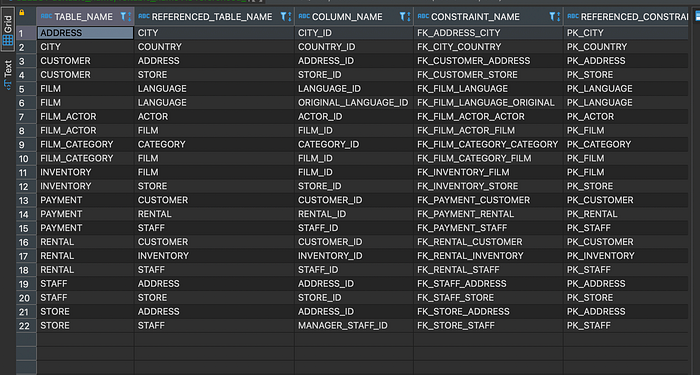
To get the one-to-many relationships of all the tables in Oracle, you can query the data dictionary views ALL_CONSTRAINTS and ALL_CONS_COLUMNS.
SELECT uc.table_name, rc.table_name AS referenced_table_name, ucc.column_name, uc.constraint_name,
rc.constraint_name AS referenced_constraint_name
FROM all_constraints uc
JOIN all_cons_columns ucc ON uc.owner = ucc.owner AND uc.constraint_name = ucc.constraint_name
JOIN all_constraints rc ON uc.r_owner = rc.owner AND uc.r_constraint_name = rc.constraint_name
WHERE uc.constraint_type = 'R' AND uc.owner = 'ADMIN'
ORDER BY uc.table_name, uc.constraint_name, ucc.position;
This query retrieves the table name, constraint name, column name, referenced table name, and referenced constraint name for each foreign key constraint in the specified schema.
Many to Many
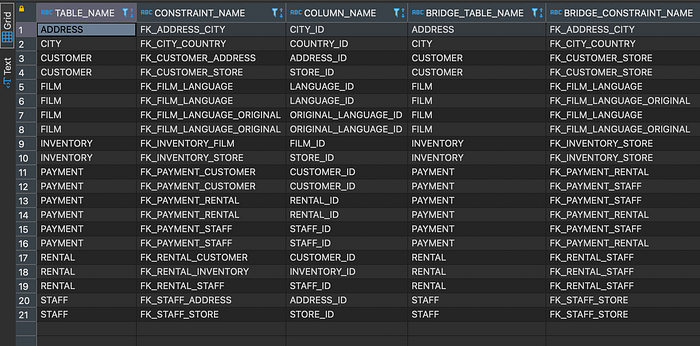
To get the many-to-many relationships of all the tables in Oracle, you need to identify the tables that are connected by a bridge or junction table.
SELECT uc1.table_name, uc1.constraint_name, ucc1.column_name,
uc2.table_name AS bridge_table_name, uc2.constraint_name AS bridge_constraint_name,
uc3.table_name AS referenced_table_name, uc3.constraint_name AS referenced_constraint_name
FROM all_constraints uc1
JOIN all_cons_columns ucc1 ON uc1.owner = ucc1.owner AND uc1.constraint_name = ucc1.constraint_name
JOIN all_constraints uc2 ON uc1.owner = uc2.owner AND uc1.table_name = uc2.table_name
JOIN all_cons_columns ucc2 ON uc2.owner = ucc2.owner AND uc2.constraint_name = ucc2.constraint_name
JOIN all_constraints uc3 ON uc2.r_owner = uc3.owner AND uc2.r_constraint_name = uc3.constraint_name
WHERE uc1.constraint_type = 'R' AND uc2.constraint_type = 'R' AND uc1.owner = '<schema_name>' AND uc1.table_name < uc3.table_name
ORDER BY uc1.table_name, uc1.constraint_name, ucc1.position;
This query retrieves the table name, constraint name, and column name for each foreign key constraint that references a bridge table, as well as the name of the bridge table and its foreign key constraint, and the name of the table that is referenced by the bridge table.
One to One
For the above schema we don’t have any one to one relations.
SELECT c1.table_name, c1.constraint_name, c1.r_constraint_name, cc1.column_name,
c2.table_name AS referenced_table_name, c2.constraint_name AS referenced_constraint_name, cc1.column_name AS referenced_column_name
FROM all_constraints c1
JOIN all_cons_columns cc1 ON c1.owner = cc1.owner AND c1.constraint_name = cc1.constraint_name
JOIN all_constraints c2 ON c1.r_owner = c2.owner AND c1.r_constraint_name = c2.constraint_name
JOIN all_cons_columns cc2 ON c2.owner = cc2.owner AND c2.constraint_name = cc2.constraint_name AND cc1.position = cc2.position
WHERE c1.constraint_type = 'U' AND c2.constraint_type = 'U' AND c1.owner = 'ADMIN'
ORDER BY c1.table_name, c1.constraint_name, cc1.position;
Queries List
To get a list of queries executed in Oracle, you can query the database’s V$SQL and V$SQLTEXT views.
SELECT *
FROM v$sql
WHERE parsing_schema_name = 'ADMIN'
ORDER BY last_active_time DESC;
This query will retrieve all SQL statements executed by the specified schema and order them by the last time they were active.

If you want to see the full SQL text of each statement, you can join the V$SQL and V$SQLTEXT views using the SQL_ID column:
SELECT s.sql_id, t.sql_text
FROM v$sql s
JOIN v$sqltext t ON s.sql_id = t.sql_id
WHERE s.parsing_schema_name = 'ADMIN'
ORDER BY s.last_active_time DESC;
This query will return a list of SQL_IDs and their corresponding SQL text for all statements executed by the specified schema, ordered by the last time they were active

Top 10 Queries
Query the appropriate Oracle Data Dictionary views to get the most run queries in Oracle.
SELECT sql_text, executions
FROM v$sql
ORDER BY executions DESC
FETCH FIRST 10 ROWS ONLY;
This will return the top 10 queries that have been executed the most frequently in the Oracle database, along with the number of times they have been executed.
Note that you need the appropriate privileges to access the various views mentioned above.
Data Extraction Strategies from Source
Common mechanisms for splitting the data during extraction include:
- Partitioning: If the source Oracle database is partitioned, then the data can be split based on the partitions, which can help in reducing the extraction time and improving the performance.
- Query-based extraction: The data can be extracted based on specific queries that are used to retrieve subsets of data from the source Oracle database. The queries can be designed to retrieve data in chunks, such as by using pagination, or by specifying a date range for the data.
- Table-based extraction: The data can be extracted table by table, where each table is extracted separately. This method may not be optimal for large databases or for databases with complex relationships between tables.
Conclusion
By performing analysis on various aspects of the database, including tables, indexes, and queries, you can get a better understanding of the data and how it is being used.
This information can then be used to design a schema that is optimized for performance and efficiency and to create a migration plan that takes into account any potential challenges or issues that may arise during the migration process.
By using the Oracle Data Dictionary, you can gain valuable insights into your database to come up with an optimized schema and migration plan.
Similar approaches can be used for other database migrations. I will try to cover this in my future articles.
Happy Analysis !!!


