Posted on December 8, 2021 by Rajesh Rajagopalan
We looked at Domain-Driven Design (DDD) for Microservices in an earlier blog. However, when you have a large and business-critical monolithic system, the strategies to decompose monolith to microservices, are slightly different. They can be further broken down based on individual business situations. Companies such as Github, Netflix, Airbnb have done a great job transforming their monoliths into microservices following the Strangler Fig approach.
In this blog, I attempt to explain how you can do this, and provide tools that you can use in your own journey. I do not intend to leave it with an “it depends” tag, but shall go into practical details of one specific approach based on my experience.
The monolith to microservices journey is rather significant, and it pays to make small, incremental steps based on the complexity and ROI for the business. The following steps, in my experience, have enabled PeerIslands help our clients in their microservices transformation journey.
- Domain-Driven Design (DDD) is still a starting point for anyone embarking on this journey. Monolith to microservices transformation is not just a technology stack upgrade, but an opportunity to re-organize your software model to match your business. My earlier blog – Domain-Driven Microservices Design from a practitioner’s view (Part 1) has more details on that.
- Select your first domain to transform
- Once you have completed your DDD, choose one critical domain to transform
- This should add value to the business and also be of sufficient complexity
- We will look at various considerations further along in the blog
- Separate data first
- Refactor cross-domain join queries
- Perform joins at the application level
- Partition/Shard data for example based on tenants, geography, etc. that will help improve performance
- Modularize code next
- Modularize your monolithic application before you start breaking it down into microservices
- Refactor the selected domain as a module
- Introduce a reverse proxy
- An HTTP reverse proxy in this case, to route all requests to your application
- This will serve as an ideal point to re-route requests to microservices when they are ready
- Build microservice for the domain that you’ve identified
- Route requests to microservice
- Define a strategy to incrementally move requests from monolith to microservice
- Validation strategy to compare old and new – we will look at tools and techniques that you can make use of
- Data synchronization between monolith and microservice until the transition is complete
- The hard way, using a custom solution
- A more effective way, using our 1Data solution
- Iterate until all domains are transformed
- Refine and refactor to optimize operations for the microservices
The rest of the blog details each of these steps.
Monolith
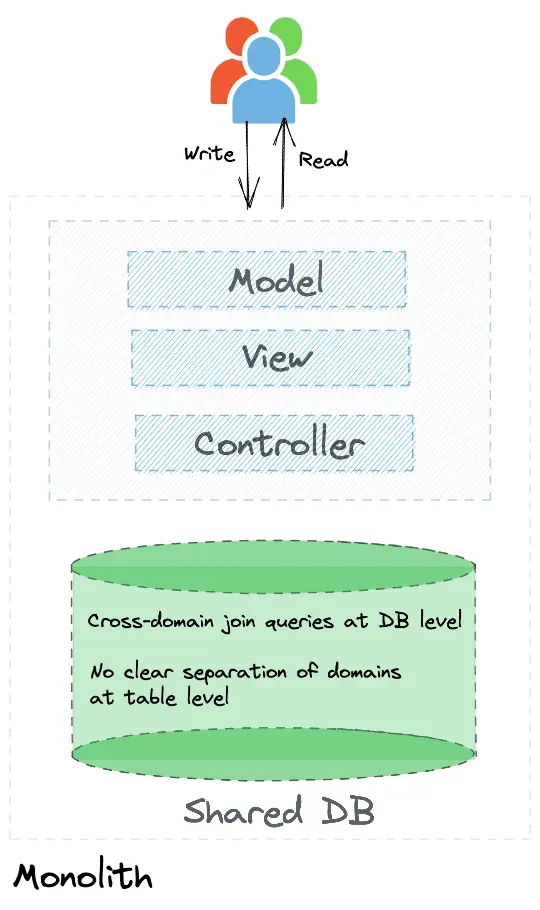
Characteristics of typical monolith include:
- No clear separation of domain boundaries in data or in code
- Reflects the legacy organization structure as described by Conway’s Law. Front-end, back-end, and database teams. Typically resulting in:
- monolithic UI,
- monolithic MVC type middleware which s tightly coupled, and
- a shared database. No clear separation of domain data. Cross-domain join queries at DB level
- Changes require extensive testing of the complete application and deployment of the entire application
- Too large with one codebase
- One build system
- One big deployment
- Longer release cycle
- All or nothing scaling
- and many more.
It’s not all bad! Many monolithic architectures have been highly successful. They are easy to understand, test and debug compared to a maze of microservices. I will not get into specifics of a monolith vs microservices but leave it at this: both have their own pros and cons, and it is never a bad idea for any new application to start as a monolith. Like Github that began with a Ruby/Rails monolith before moving to a microservices architecture after almost 12 years. As the complexity of the application/product grows, having a microservices architecture will make you much more agile.
So how do you break down a monolith into microservices? Data first or code first?
Separate data first
Separate data based on clearly defined domains (which should be preceded by a DDD). If we take an e-commerce example, a database with clearly segregated domain data would look like this.
(Note: Each box such as Inventory is not a single table but several tables in a database such as MySQL with constraints, foreign keys, and so on.)
I would pick one business-critical domain that adds value by way of transformation, and is also of sufficient complexity. Once you have selected that domain, separate the data first.
While this approach of selecting a sufficiently complex domain comes with increased overall complexity, it would serve as an ideal playground to define and refine your overall process and techniques and learn for your overall transformation initiative. And this exercise will also result in measurable value to your business.
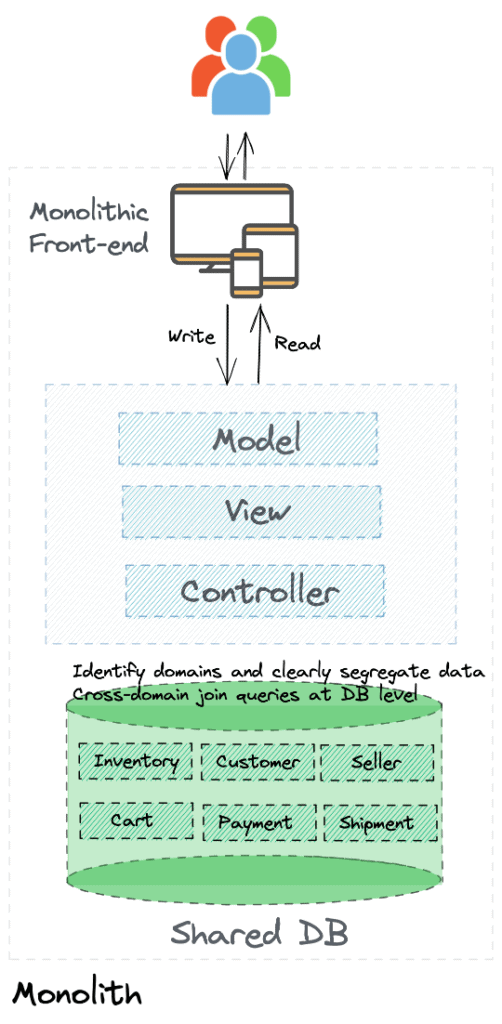
While the above picture shows data for all domains separated, you would approach this incrementally.
Refactor cross-domain join queries
Typical legacy shared databases include cross-domain join queries performed by the database. One of the first tasks of breaking down a monolith will require us to identify and refactor such cross-domain join queries. And move any joins required to the application layer level. While these cross-domain join queries are very handy, they violate an important principle of microservices: a service does not directly access data from another domain’s database, to avoid tight coupling.
Moving such joins to the application level will likely introduce:
- Latency, as we will get parent entities first and then lookup child entities. The database would have performed them using joins
- Data consistency challenges as the database would no longer enforce constraints such as foreign-key relationships
However, there are several techniques to mitigate the latency and consistency issues.
- Reduce latency by caching required data locally within a domain
- Check relationships before inserting or deleting records to avoid data consistency issues
While these approaches result in some short-term pain, in the long run, the application and database become much cleaner with clear domain boundary separation, making it easier to break down the monolith into microservices.
Partition/Shard data
Partition data based on tenants, geography, or any other appropriate dimension for your business. This will help both in the short term to improve performance, and in the long run, to migrate a single tenant or geography to microservices architecture once it is time.
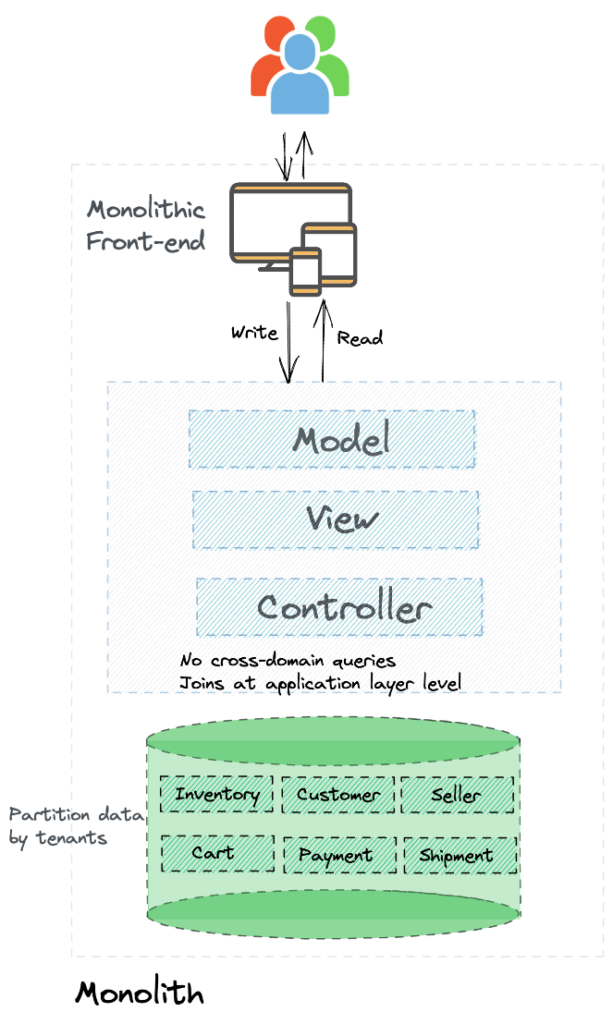
Reference data
Move reference data to a shared schema. Sharing data between domains does bring up several challenges, like any change to the schema that might impact all services that are using the data. However, as long as you keep this to a data set that is fairly static and whose schema changes are rare – primarily lookup data – the benefits offset the potential challenges.
However, if you have any reference data that does not conform to the above characteristics, then the best way forward is to keep it within respective domains even if you have some duplication of data. Such duplication is not bad at all.
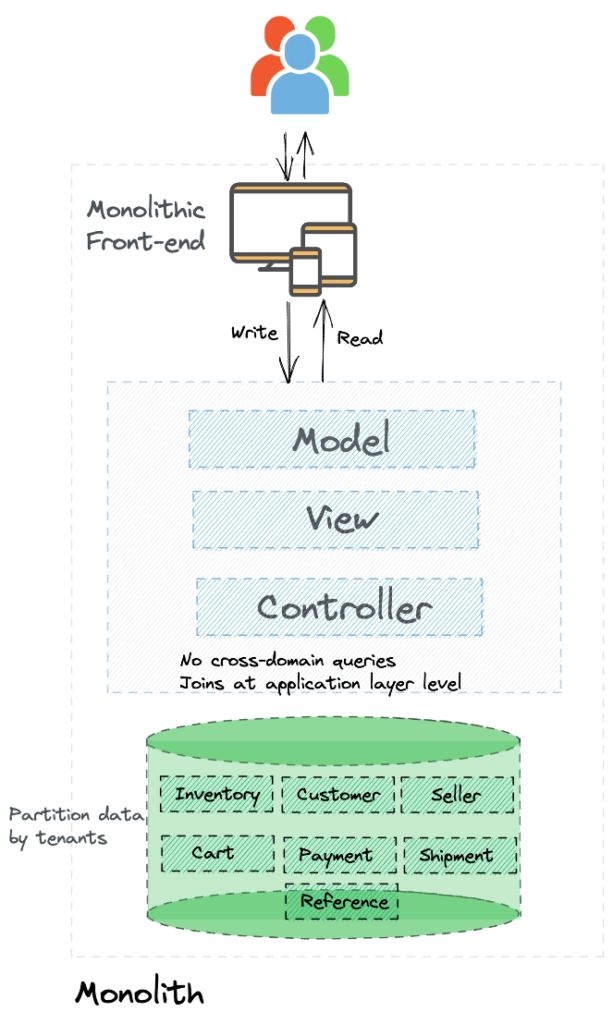
Modularize your application
The next significant step is to modularize your monolithic application, starting with the first domain identified. You can continue to have the MVC architecture if you already had one, but modularize the code. For example: modules in Spring or engines/gems in Ruby on Rails.
While doing this, remember to validate that the new functionality not just works as expected, but also compare it against the original functionality. No amount of test cases is going to cover all the production scenarios. Tools such as Scientist that Github used in their journey will come in handy. Refer to the tooling section for more details.
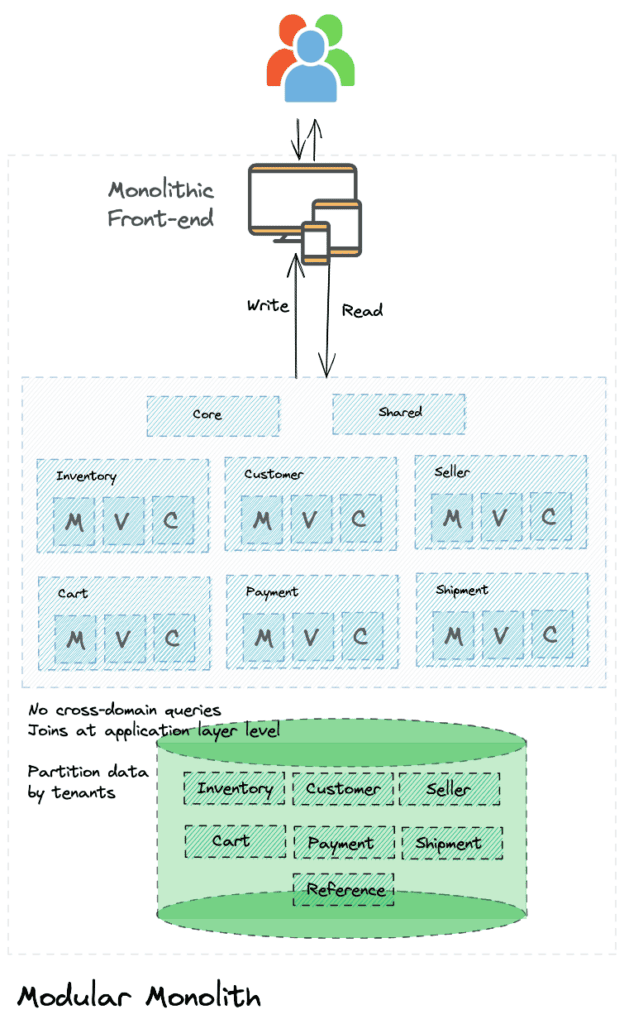
We have now decomposed the legacy monolith into what we can call a “modular monolith”. We are now ready to move this “modular monolith” into a microservices architecture.
Again like we did with the database, the above picture represents the entire codebase modularized. Based on the state of your codebase, you would ideally do this incrementally starting with the first domain identified for transformation.
Introduce an HTTP reverse proxy
All requests to the monolithic application are routed through an HTTP reverse proxy. This pattern allows us to have fine-grained control over how requests are routed. This will be a key component when we start moving requests out of the monolith to the new microservices.
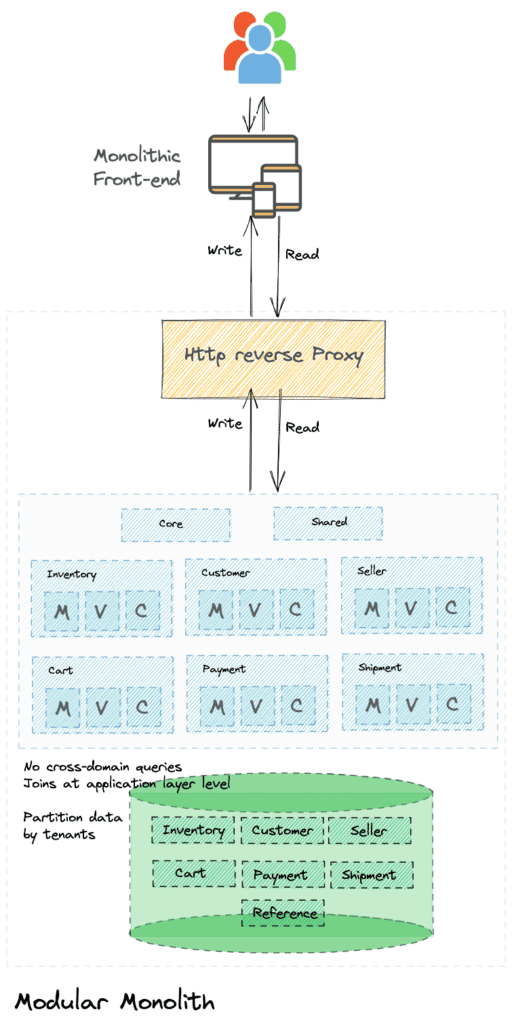
Building Microservices
In addition to the approach of selecting a domain with sufficient complexity and business value, you can also consider one of the following as a starting point:
- Core services and shared services such as AuthZ and AuthN.
- A new capability that you are adding; it can be built directly as a microservice
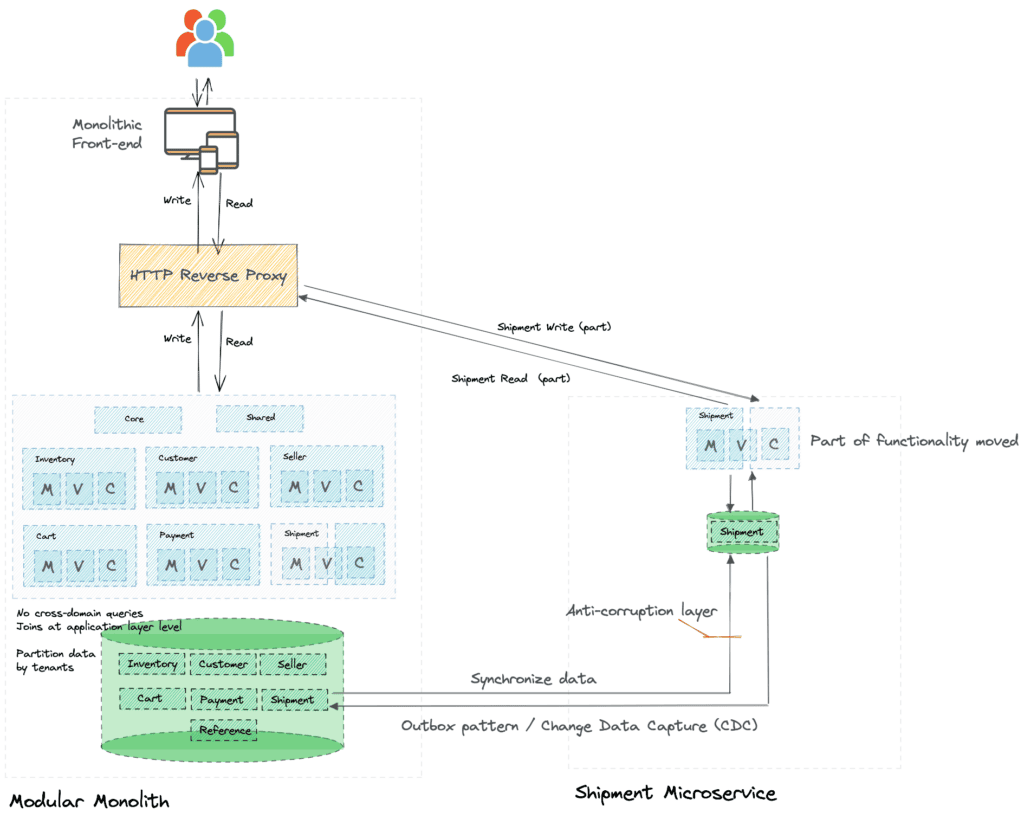
Route requests to microservice
One of the key aspects of continuous delivery is the ability to separate deployment from the software/service release process. You can deploy a piece of software into production without actually making it available to users or other services. In our case, assume you have the new Shipment microservice being built. You can deploy it in production right from the get-go, and start routing requests to the microservice when meaningful functionality is ready. You can route only requests for only such completed features to the new microservice while routing other requests to the monolith.
The other option is routing requests for a pilot tenant or geography to the new microservice, and the rest to the monolith.
Once the new microservice is sufficiently tested and is mature, you can route all requests to the new microservice.
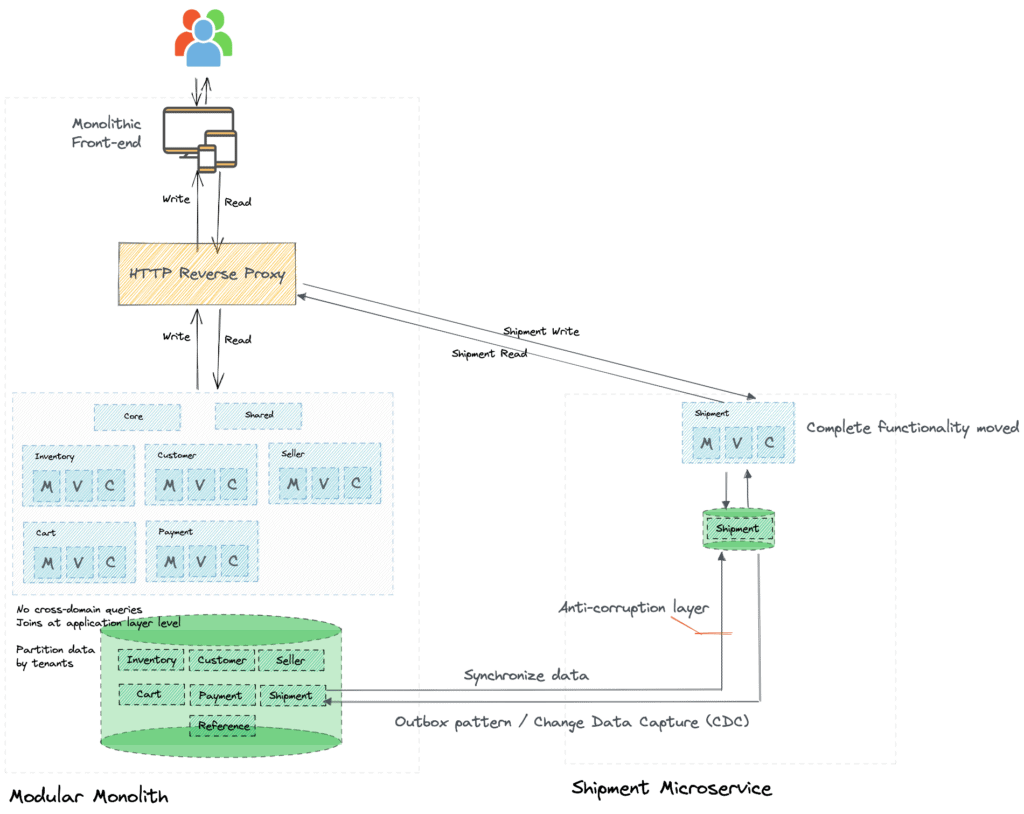
Data synchronization until the switch
The main benefit to adopting an incremental approach is that you mitigate the risk of the new microservice not working as expected. You allow the new service to mature over time, which allows you to work out the kinks before switching over fully.
This requires data synchronization between monolith and microservice for a prolonged duration. While there are many approaches to achieving this synchronization, using an outbox pattern coupled with Change Data Capture (CDC) has been proven successful.
The other side effect of such gradual migration to microservice is that the new microservice will require some data from the legacy monolith. You need to ensure that the new microservice is not polluted by the legacy monolith design. You will need to build an anti-corruption layer to achieve this.
Representative example
Let’s look at a defined example:
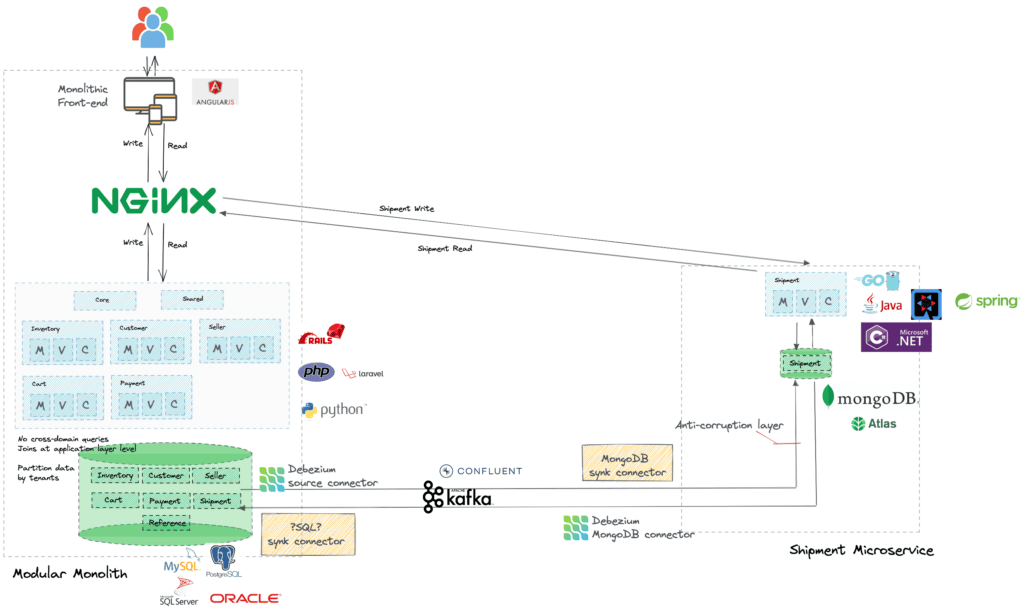
As you can see there is a lot going on when it comes to maintaining data synchronization during the gradual transition to microservices architecture. Operating such a tooling setup for a long period of time will require significant effort.
We built 1Data, a tool that extracts all the tooling and process complexity, to allow you to focus on moving your monolith to microservices.
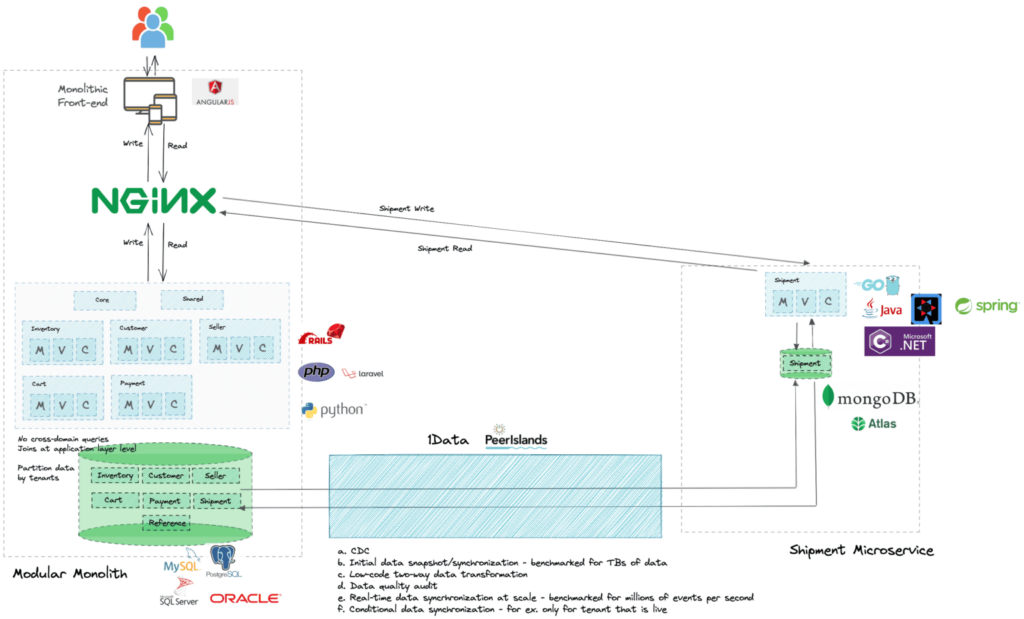
1Data comes with:
a. CDC and synchronization capability built-in. We use Debezium, Confluent Kafka and Kafka Connect for respective targets.
b. Initial data snapshot/synchronization – benchmarked for TBs of data. We use Databricks/Spark for the same.
c. Low-code two-way data transformation. All the configurations can be generated using a simple configuration.
d. Data quality audit through the lifecycle.
e. Real-time data synchronization at scale – benchmarked for millions of events per second.
f. Conditional data synchronization – for example: only for a tenant that is live on the microservice.
Tooling
There are several tools available that can help in your journey from monolith to microservices. Look to reuse or adapt them in your context. It’s not all about heavy lifting.
- Scientist is a library for refactoring critical paths in your code. Originally developed by Github during their monolith to microservices journey it focussed on Ruby on Rails code. We now have forks for Java, C#, and other languages as well.
- Scientist: Measure Twice, Cut Once | The GitHub Blog
- Note: Use this tool only for code that does not have any side-effects – for example, writes to the database.
- github/scientist: A Ruby library for carefully refactoring critical paths.
- rawls238/Scientist4J: A port of Github’s Refactoring tool Scientist in Java
- scientistproject/Scientist.net: A .NET library for carefully refactoring critical paths. It’s a port of GitHub’s Ruby Scientist library
- mpcabd/pyentist: Python Scientist – Port of GitHub’s Scientist – A library for carefully refactoring critical paths
- trello/scientist: A Node.js library for carefully refactoring critical paths in production (github.com)
- CodeScene: a social code analysis tool to find the most lively components.
- IBM Mono2Micro – Using AI to refactor Java monoliths into microservices
- Home – vFunction – Modernize More Apps Faster
- Tool similar to IBM Mono2Micro
- SonarGraph-Explorer: identify component dependencies
- Structure101 – Software Architecture Development Environment (ADE). Dependency and structural code analysis tool.
- Use code toxicity analysis tools such as CheckStyle to make decisions around rewrite vs. reuse.
- SchemaSpy
- SchemaCrawler
- Feature flags: There are many tools available that can help towards the “deploy code but control when you release” strategy.
- Or build custom tools like
- Github – Query Watcher. Set up alerts to detect queries that cross functional boundaries.
- Shopify Wedge that tracks the progress of each component towards its goal of isolation.
Exclusions
We did not go into details of the UI application – how a monolithic UI app can be decomposed and maybe even move towards a micro-frontend architecture. While the same principles apply, the tools, technique, and approach would be very different and maybe we can explore that in a separate blog of its own in the future.
Conclusion
While this is an attempt to go beyond “it depends” and dig into details and provide an approach that you can follow for your monolith to microservices migration, you can easily see why most books and articles take the “it depends” route. The business situation and technology stack are numerous, with “n” different practical scenarios to consider. I’d love to hear about your experience and the route you have taken in your journey.
References
- GitHub’s Journey from Monolith to Microservices (infoq.com)
- The Human Side of Airbnb’s Microservice Architecture (infoq.com)
- gotocon.com/dl/goto-berlin-2014/slides/AdrianCockcroft_MigratingToCloudNativeWithMicroservices.pdf
- How to break a Monolith into Microservices (martinfowler.com)
- Monolith to Microservices (oreilly.com) by Sam Newman
- Dissecting our Legacy: The Strangler Fig Pattern with Apache Kafka, Debezium and MongoDB @ VoxxedDays Romania 2021 – Speaker Deck
- My blog is inspired by a clear and visual approach presented in the talk “Dissecting our Legacy” by Hans-Peter Grahsl and Gunnar Morling.
- Reliable Microservices Data Exchange With the Outbox Pattern (debezium.io)


