Posted on June 1, 2021 by Rajesh Vinayagam
Earlier articles Part 2 & Part 4, focused on using native tools for Initial Snapshotting & Change Streams with Kafka Mongo Sink Connectors for migrating the ongoing changes respectively.
In this article we will see how we can leverage Spark Connectors for CosmosDB and MongoDB for doing the Initial Snapshotting and CDC.
Native Tools ( mongodump, mongorestore) will take considerable time for copying over the data from the source not leveraging the complete RU offered by CosmosDB or the power of Atlas Cluster
With Spark Connector for CosmosDB, we can copy huge volume of data from Cosmos to blob storage as parquet or json files. With right sizing of spark cluster the data can be copied to blob storage in no time.
High Level Design
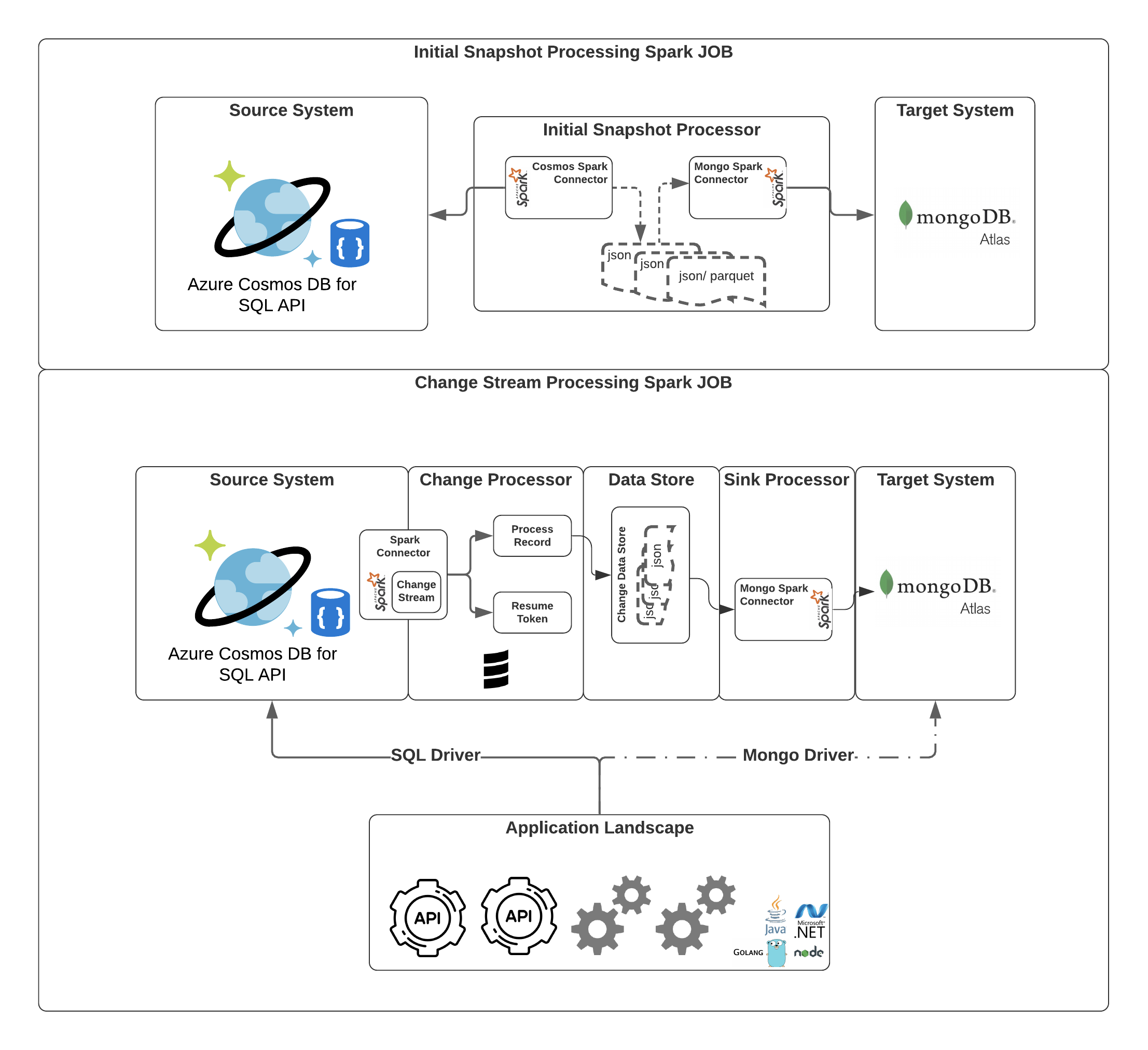
Data Extraction
Spark Connector for Azure Cosmos DB to get all the data from CosmosDB.
In the below code snippet we initialised the spark context and setting up the cosmos configuration
- Endpoint
- Key
- Database
- Collection
- Query
Use the Config to read the cosmos collections as dataframes.
Later write the dataframes to a parquet or json file.
PS : Explore the various option of Cosmos spark Connector here.
Initially I had trouble setting up the required versions of spark and scala for the Cosmos Spark Connector to work. Please look out for compatibility settings in the repository code.
https://github.com/PeerIslands/cosmo-spark-processor.git

Data Loading
Spark Connector for MongoDB to push the data.
In the below code snippet we set up the spark context and the config object with required MongoDB settings to Initialise MongoSpark with spark context.
Later read the raw parquet or json file that was extracted from Cosmos to a DataFrame and use the MongoSpark save to write the data to MongoDB

PS : Explore the various option of Mongo spark Connector here.
The above design was just one flavour of spark for data migration and was working seamlessly to prove the idea of the design.
https://github.com/PeerIslands/mongo-spark-processor.git
With spark connectors for both MongoDB and CosmosDB there are endless options that can be explored.
With this I will end the Azure CosmosDB for Mongo Series. Will catch you with one other interesting series until then stay tuned!!!.


