Posted on July 7, 2021 by Rajesh Rajagopalan
Introduction
Over the past several years, organizations have begun transforming their monolithic applications to microservices architecture, using cloud-native solutions in most instances. The primary reason for this migration is the improved agility provided by the microservices architecture, which allows for multiple product releases every hour, scales services independently, with improved resilience. Microservices architecture when done right, especially following DDD (Domain Driven Design), speeds up the transformation so businesses can accelerate and meet their business needs.
While application design has witnessed a shift toward decentralized microservices for bounded contexts, the analytics landscape of organizations has continued with centralized and monolithic solutions. Centralized data warehouses were quite popular until a couple of decades ago. The last decade in particular has seen the evolution of AI & ML and monolithic data lakes as a source to fuel these solutions.
As seen with the application landscape, organizations are realizing that the increasingly complex and monolithic data landscape cannot keep with the pace of change in their analytical business requirements. Centralized data warehouses and data lakes are not able to keep pace with the increasing complexity of analytics, AI and ML needs of businesses.
Data mesh first introduced by Zamak Dehghani, is an architectural pattern that takes a domain-oriented approach to data, very much like the microservices pattern for applications. Decentralized ownership of analytic data, aligning to the domain bounded contexts. While there are several organizations experimenting with initial implementations of data mesh, there are several gaps to be filled before organizations get to mature implementations.
In this blog, I explore the challenges with centralized approaches of data warehouses and of many data lake implementations, what a data mesh is, and how it solves some of these challenges. In addition, I will try to address some common misconceptions regarding data mesh, the challenges faced as you start implementation, and finally look at a practical implementation example that would help understand data mesh.
Data warehouses
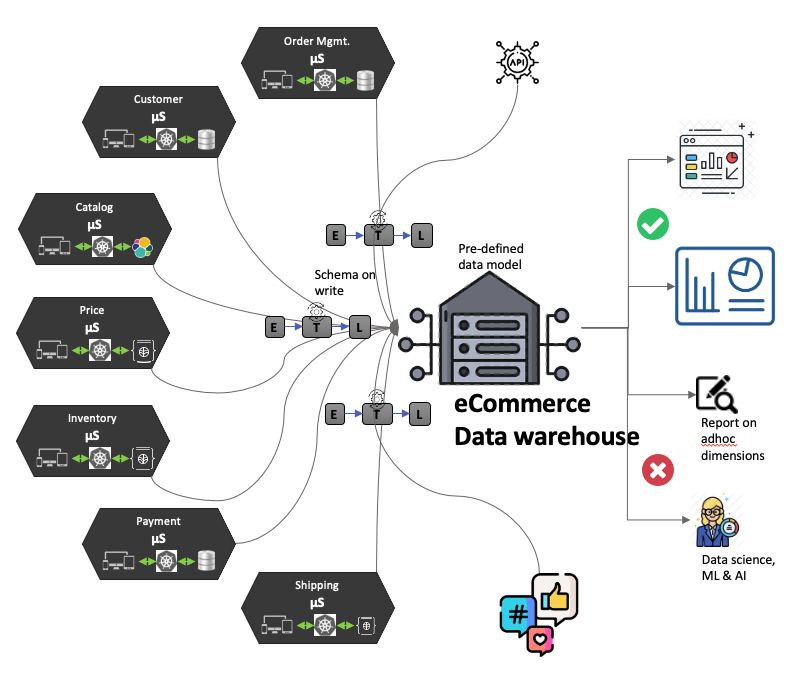
Figure 1: E-commerce data warehouse system and its limitations
Data warehouses have come a long way since the days of Bill Inmon’s top-down topology, and Ralph Kimball’s introduction to bottoms-up topology. With multiple data marts feeding into a data warehouse, they are now the de facto standard of dimension modeling. However, their general characteristics have remained the same.
- Stores structured data for the organization in a common data model
- Schema on write (pre-defined models)
- Stores only processed data
- Centralized data ownership and architecture
- Inmon vs Kimball model of data warehouse feeding data marts, or vice versa
- Most data warehouses follow SQL based query language
While they have served organizations very well in their business intelligence journey and continue to do so, the data explosion witnessed in recent times has exposed several limitations of the approach.
- Data is aggregated so visibility into the lowest levels is lost
- Only pre-determined questions can be answered
- Modeling a single unified data model with required facts and dimensions is impractical for large organizations with complex domains. This is one of the primary reasons for high failure rates for DWH initiatives across organizations
- Siloed data engineers who specialize in building data pipelines but don’t have complete knowledge or domain expertise in either source systems or how business users would use the processed data
- A complex labyrinth of data pipelines with constant operational challenges for centralized data teams
While solutions such as those from Snowflake technically break down the monolith by splitting compute and storage, from a domain standpoint, data warehouses still remain a monolith.
Data warehouses store only pre-aggregated data and are limited by the questions they can answer. Data Lake, on the other hand, stores raw data which allows it to answer ad-hoc questions that are not known at the time of creation.
Data lakes
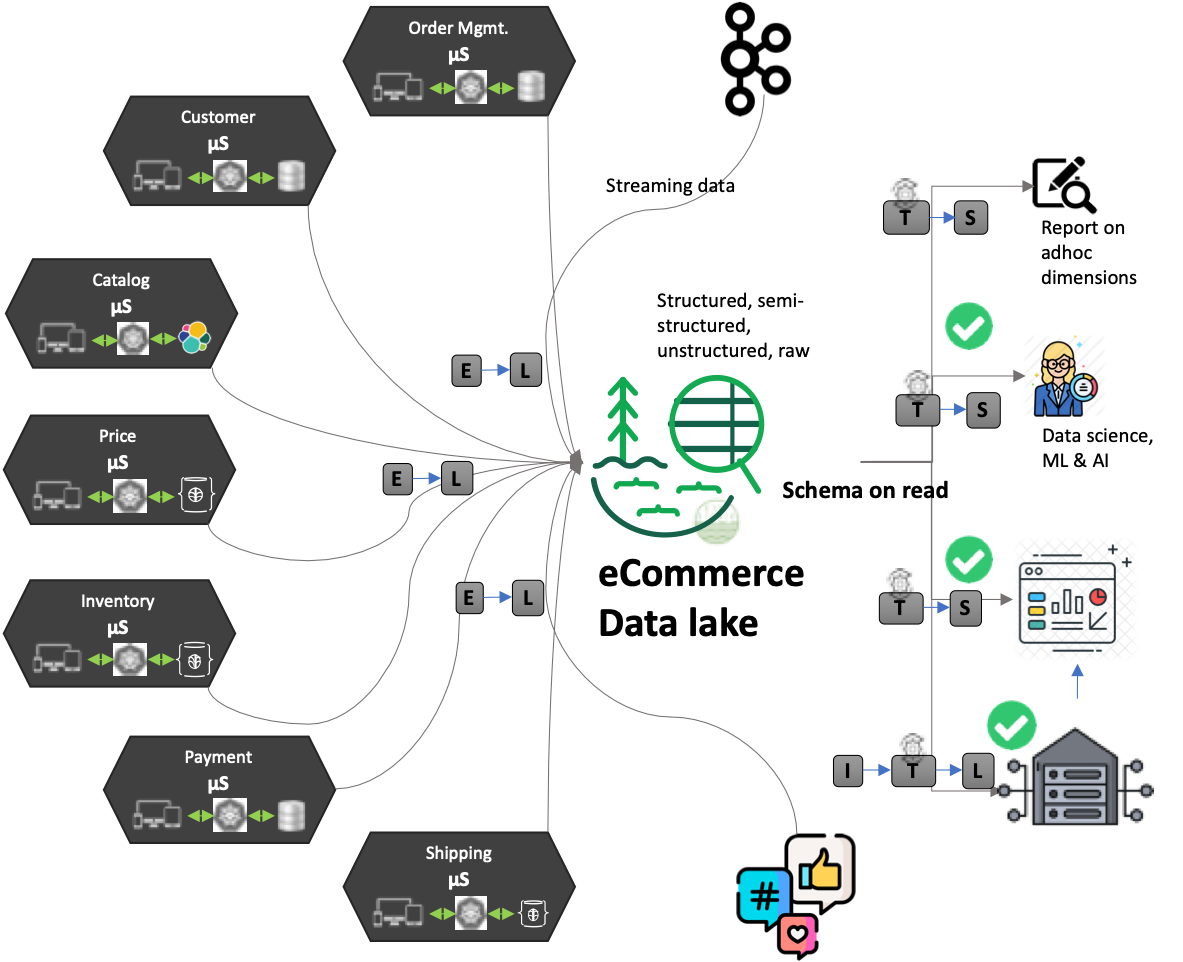
Figure 2: E-commerce data lake and its complexities
Data lakes as envisioned by James Dixon began as:
- Immutable storage of raw data – structured, semi-structured, unstructured data
- Schemaless – the user of the data lake determines and interprets the schema based on their requirement leading to “schema-on-read”
- Single source of data or data from a single domain. You can have multiple data lakes when you have a complex domain with multiple bounded contexts. Each with a data lake of its own. James Dixon called it a “water garden”
- Data is aggregated when required so that visibility into the lowest levels is not lost. Data warehouses use data lake data as a source for their aggregated dimensions and views
- Choice of multiple query languages and SDKs
While the original vision addressed many of the challenges with data warehouses, the implementation quickly deteriorated into what we call a “data swamp;” massive repositories of data that do not provide any value to the users. A centralized monolith that is difficult to manage operationally. Organizations typically have a single monolithic data lake across multiple domains resulting in:
- Complex data pipelines: A complex labyrinth of data pipelines managed by data engineers who don’t have a sufficient understanding of source systems or the consumers. Failed production jobs leave data in a corrupt state with complex recovery procedures leaving data consumers with constant operational challenges
- Data quality: Unless organizations have a process of continuous data validation and quality management, most data lakes quickly morph into data swamps
- Continuous data management: There is a constant change to the source data, and organizations need a way to update, merge or delete data in the lake. The immutability of data presents a number of challenges when it comes to achieving this reliably. Newer implementations such as Delta Lake look to solve this problem
- Governance: Limited data governance and security are seen in most implementations
- Query performance: Without proper management of data indexing, partitioning, and management of smaller files, query performance deteriorates
- Metadata management: Data lakes that grow to become multiple petabytes or more can become bottlenecked not by the data itself, but by the metadata that accompanies it
- Above all, data is centralized leading to a monolithic data lake
What is a Data Mesh and how does it solve these problems?
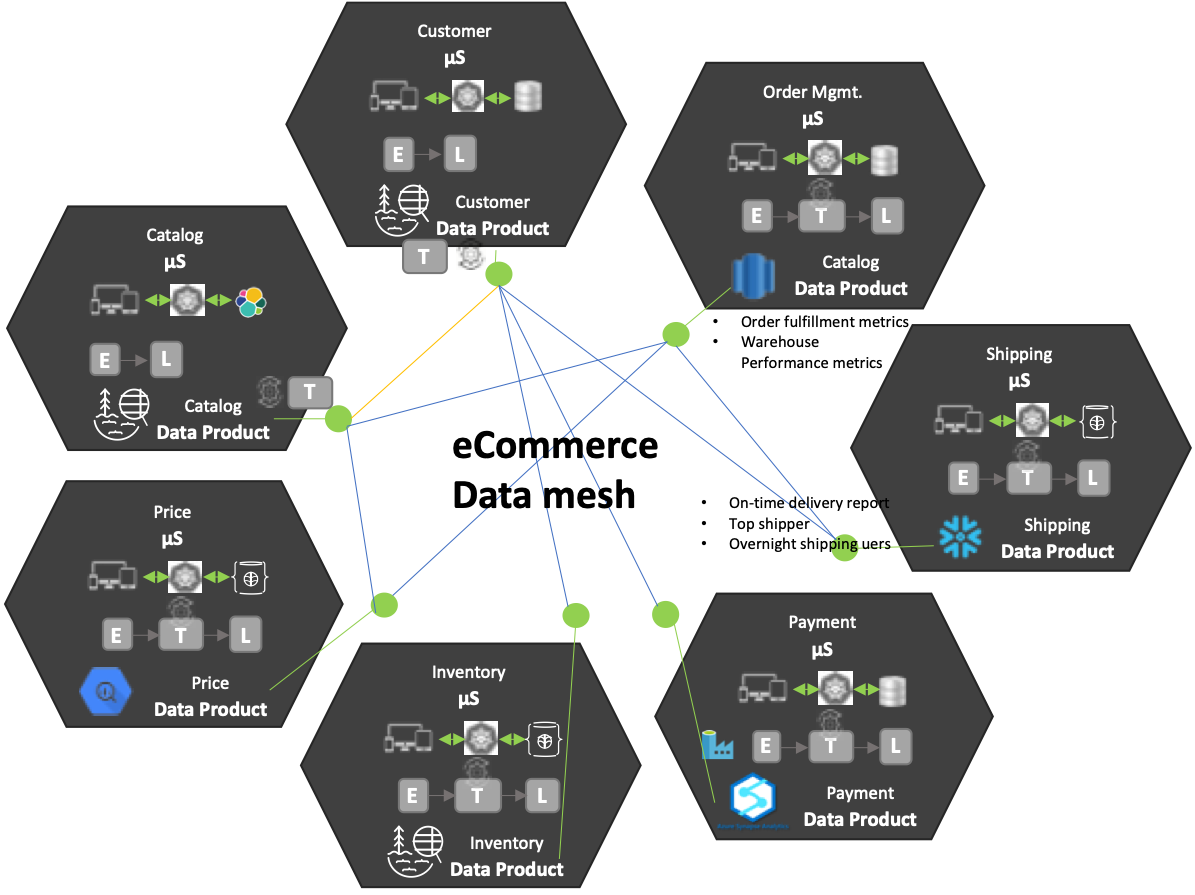
Figure 3: Data mesh with focus on domain and decentralized ownership
A centralized data platform, with a centralized team that owns and curates the data from all domains, is neither effective nor a scalable solution. As we discussed above, much like monolithic applications, monolithic and centralized data warehouses and data lakes are not scalable, have operational complexity, and slow down the pace of developing data-centric solutions.
Data mesh architecture on the other hand:
- Focuses more on business domains, rather than technical implementation
- Results in domain-oriented, decentralized data ownership and architecture
- Allows each bounded context to own and make available its domain data as “data product”
- Leaves the choice of storing raw or aggregated data to be determined by individual bounded contexts based on users
- Pushes data processing pipelines into each bounded context who own and understand the data
When DDD is diligently followed, each bounded context in our example already has ownership of operational services and data. In addition, the ownership of analytical data would belong within the analytical data plane of the bounded context. This could include:
- data storage – data lake or data warehouse based on how the bounded context chooses to expose its data product
- data processing pipeline
- data governance, etc.
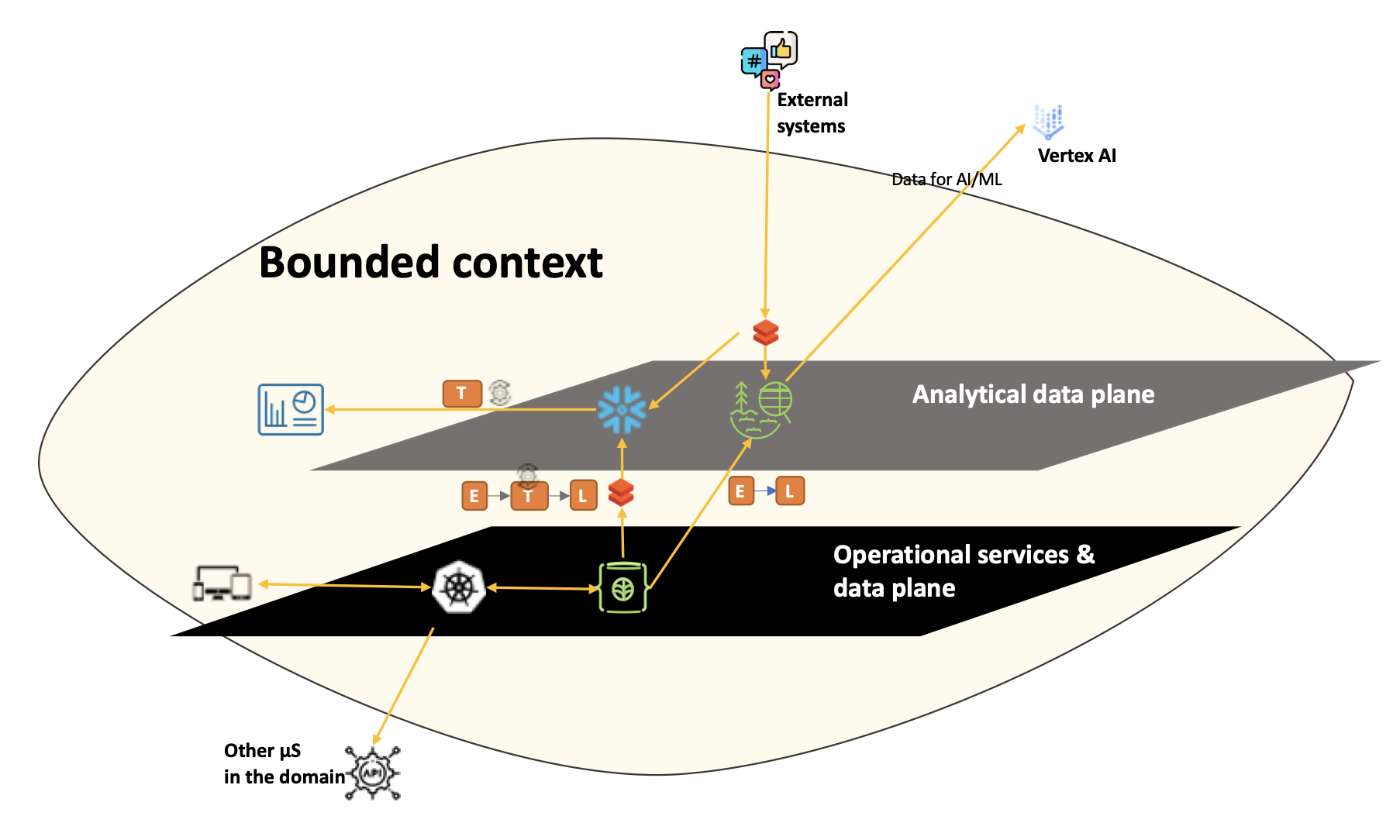
Figure 4: Bounded context with operational data plane and analytical data plane
As with microservices architecture, data mesh encourages polyglot technology solutions for each data product – based on the requirement. One bounded context could have a Big Query data warehouse and another a MongoDB data lake. However, each bounded context needs to have a defined and interoperable solution for data discovery and governance. The following diagram illustrated in Zamak Dehghani’s blog brings this out neatly.
Characteristics of a domain data product
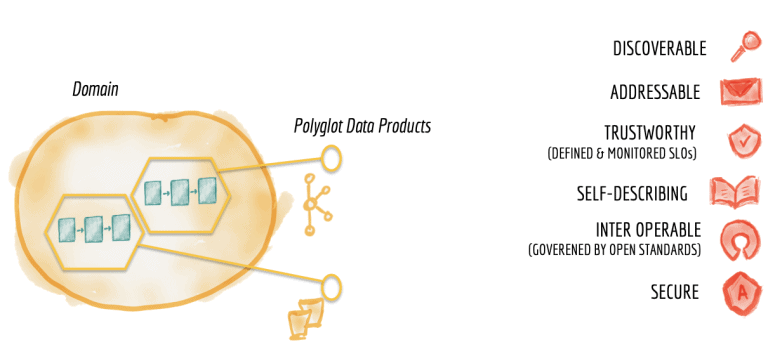
When following DDD, the development teams are organized around bounded contexts. Each team has the required skills to build the full stack of services demanded by the bounded context. Similarly, when building a data mesh, domains that make data products available need to be augmented with new skill sets as well:
- the data product owner and
- data engineers
Data Mesh – infrastructure
Having a polyglot and decentralized solution does not necessarily mean every bounded context has to manage its own data warehouse, data lake, and so on. Organizations can build a domain-agnostic data infrastructure that allows for self-service by respective bounded context teams.
Infrastructure and cloud-native solutions required by domain applications have seen rapid development over the last decade. Examples being containerization of services, container orchestration using Kubernetes, service discovery, service mesh (Istio), service proxy (Envoy), serverless function infrastructures such as Lambda, observability tools such as New Relic, Data Dog, multiple choices for operational databases such as MongoDB, PostgreSQL, etc. and many more solutions. The equivalent infrastructure that a Data Mesh architecture requires still has a long way to go. While the foundational infrastructure for the analytical data plane already exists – including data storage, processing, etc., – the data mesh architecture requires a number of capabilities to further develop or in many cases adopt existing technologies to the distributed environment.
- Data catalog and discovery
- Data governance
- Data product lineage
- Observability toolset
- Data quality management
- In-memory data caching
Data Mesh – challenges to solve for
While data mesh architecture helps develop a cleaner analytical data architecture with decentralized ownership of domain data, there are several technical challenges to solve, anti-patterns to be aware of and operational processes to be developed along the way.
While exploring the challenges and potential solution options in detail will require a blog of its own, in the section below, I will attempt to summarize the challenges of a data mesh implementation.
Organizational change management considerations
- Monolith to microservices transformation is not just a technical undertaking. It involves an organizational change that needs to break down the overall domain into business contexts, teams organized to own and develop various layers of solution required by the business context, and so on. Moving from a monolithic data landscape to a data mesh involves similar reorganization. Augmenting existing teams owning bounded contexts with data engineers. It is as much an organizational change management as it is technical
- Organize teams around the Data Domain, not tooling
- Organizations would do well to also plan for training their teams on the cultural shift. Product owners, product managers in particular, and the rest of the team need to start thinking about data as a product
- Instead of having a monolithic data lake and data warehouse to serve the needs of the organization, we now have domain data products. The role of a Chief Data Officer becomes even more important – guiding various teams on data strategy, what constitutes a data product, how they can be managed and served, and so on.
Technical challenges to solve while realizing a data mesh implementation
With a microservices architecture, we solve tasks around multiple microservices, optimized communication between microservices, orchestration when more than one microservice is involved. When dealing with a data mesh, data scientists have similar problems to solve for. And the toolset required to solve these problems is still evolving.
- How can we enable domains to combine data available across multiple data products without having to duplicate data or copy it over? In the above e-commerce example, while each domain such as customer, inventory, shipping, order management, etc. have their own data product, how can we analyze data that would generate metrics and analyze trends across all of them? How can we relate shipping metrics with that of inventory? Do we need to copy data over from inventory data product to shipping domain?
- We will need a sophisticated and mature data virtualization solution that helps pull data across data products together without having to copy them over or duplicate them
- Delta lake and its newer solution of Delta live tables (Delta Live Tables – Databricks – Databricks), I believe, is an interesting development that will help in this area
- How can we share data reliably across technology stacks and cloud platforms?
- Delta sharing protocol recently announced looks to be one in the right direction. I for one will keep an eye on how this evolves. Delta Sharing – Delta Lake
- Interoperability and standardization of communications for domains accessing data products available in other domains. How can this be implemented in an optimal way? Consider one domain that requires row-level, raw data from another domain that could be terabytes in size. How can we enable this? How can we standardize the interoperability of the data dictionary across domains and technology stacks?
- Discoverability: much like service discovery in the case of microservices, how can we enable data product discoverability?
- Not to forget metadata management which in itself is a massive field of its own. Do we have a common metadata layer across data products or distribute that as well? Does that help or add to the complexity of data mesh implementations?
- GCP Data Catalog is a fully-managed, highly scalable data discovery and metadata management service
- On top of all these, organizations are increasingly moving toward multi-cloud and cloud-agnostic solutions. How does this play into data mesh implementations? It definitely adds to the complexity of interoperability and many other areas
Pitfalls and anti-patterns to be aware of
- While we focus on decentralized ownership, we need to be careful about not ending up with a fragmented system that would require data analysts and scientists to sift through a myriad of warehouses and lakes to solve their problems. A fragmented data landscape without the required tools for data discovery and consumption is a bigger challenge than a monolithic one
- Fuzzy boundaries and data product definitions can lead to duplicated and unusable data products
- Like microservices, data mesh is not a solution for all. A monolithic data lake or data warehouse may be a good answer for small organizations. We ideally need a framework/scorecard that can help organizations easily determine the ideal solution approach
Operational processes to be developed
- Data governance processes and tools including catalog, lineage, etc. need to mature to handle distributed data products
- The recent GAed Azure Purview, (Azure Purview for Unified Data Governance | Microsoft Azure) I believe, is a great tool to solve our problem. It provides automated data discovery, lineage identification, and data classification across on-premises, multi-cloud, and SaaS sources
- Data security – how can we enforce access controls and security requirements consistently across data products?
- Observability – how can we build observability including monitoring, alerting, logging within data products, and also have a view across data products?
This section highlights challenges and key considerations to keep in mind while embarking on a data mesh implementation journey. I will explore possible solutions in detail in a follow-up blog.
While there are a number of challenges to be overcome in realizing a data mesh implementation, for complex domains and large organizations, it is an ideal solution to build distributed and decentralized data architecture.
Organizations and their early Data Mesh implementations
A number of organizations have taken early steps towards data mesh implementations.

Frameworks and tools under development that would eventually contribute to a mature data mesh implementation
- Apache Atlas: open metadata management and governance capabilities. https://atlas.apache.org/
- Dremio: live, interactive queries directly on cloud data lake storage. https://www.dremio.com/
- GCP Data Catalog: Fully-managed, highly scalable data discovery and metadata management service. https://cloud.google.com/data-catalog/
- Apache Beam: unified programming model to define batch and stream processing. https://beam.apache.org/
- Databricks: powered by Delta Lake, the Databricks Lakehouse combines the best of data warehouses and data lakes. https://databricks.com/
- MongoDB data lake: query and analyze data across operational and data lake storage. https://www.mongodb.com/atlas/data-lake
and many more.
Looking forward
While organizations are taking their first steps towards a data mesh architecture, there is a long way to get to a mature implementation. A number of tools, frameworks, and technologies to be developed. Prime among them being a data mesh standard. And sharing and exchange of practical implementation experiences.
References
- Data Lakes Revisited | James Dixon’s Blog (wordpress.com)
- DataLake (martinfowler.com)
- How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh (martinfowler.com)
- Data Mesh Principles and Logical Architecture (martinfowler.com)
- Google Chrome – March 18 Webinar with Dave McComb – Google Slides (loom.com)
- Data Lake Challenges – Databricks
- Data mesh user journey stories : datamesh (reddit.com)
- Data Mesh defined | James Serra’s Blog


